-
Lets face it, there’s lots of things the web client sucks at. Using a console window in the browser is one of them.

This bar at the top of the console window just takes up space. How about a useful hint, tell me how to get rid of this to make more use of the screen.
Read More -
By accident while in Cluster Settings / Datastore Heartbeating, I noticed a datastore wasn’t available of one of the hosts.
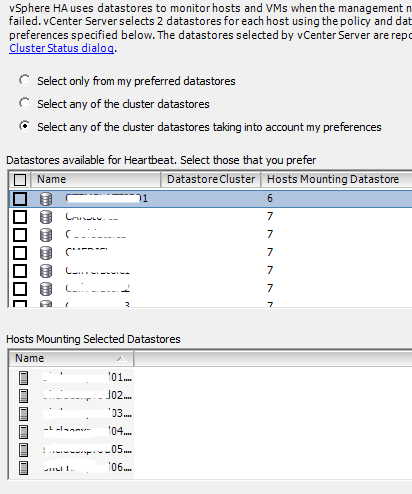
Trying to mount it from the vSphere client failed with a popup:
Call “HostStorageSystem.ResolveMultipleUnresolvedVmfsVolumes” for object “storageSystem-326” on vCenter Server “vcenter” …
Read More