-
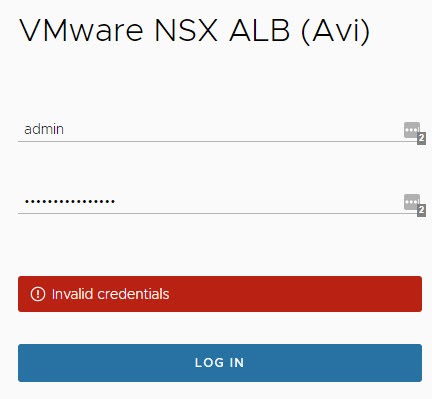 Uh oh. You don't know the NSX ALB admin password, but if you have have another local account with Super User access, you can reset the admin password.
Uh oh. You don't know the NSX ALB admin password, but if you have have another local account with Super User access, you can reset the admin password.
Read More -
By accident while in Cluster Settings / Datastore Heartbeating, I noticed a datastore wasn’t available of one of the hosts.
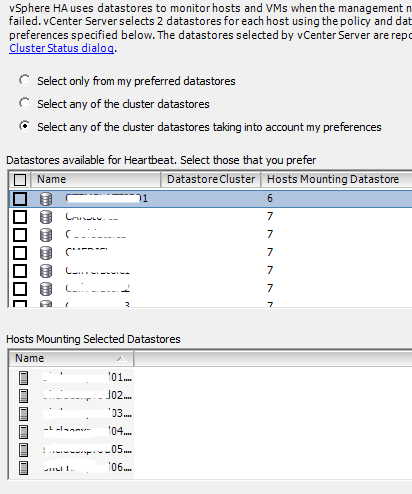
Trying to mount it from the vSphere client failed with a popup:
Call “HostStorageSystem.ResolveMultipleUnresolvedVmfsVolumes” for object “storageSystem-326” on vCenter Server “vcenter” …
Read More